文本分类&聚类
按照处理的对象和处理的方法不同,可将常见文本分类/聚类任务分为以下几种:

要实现上述目的,通常有以下几个核心问题要解决:
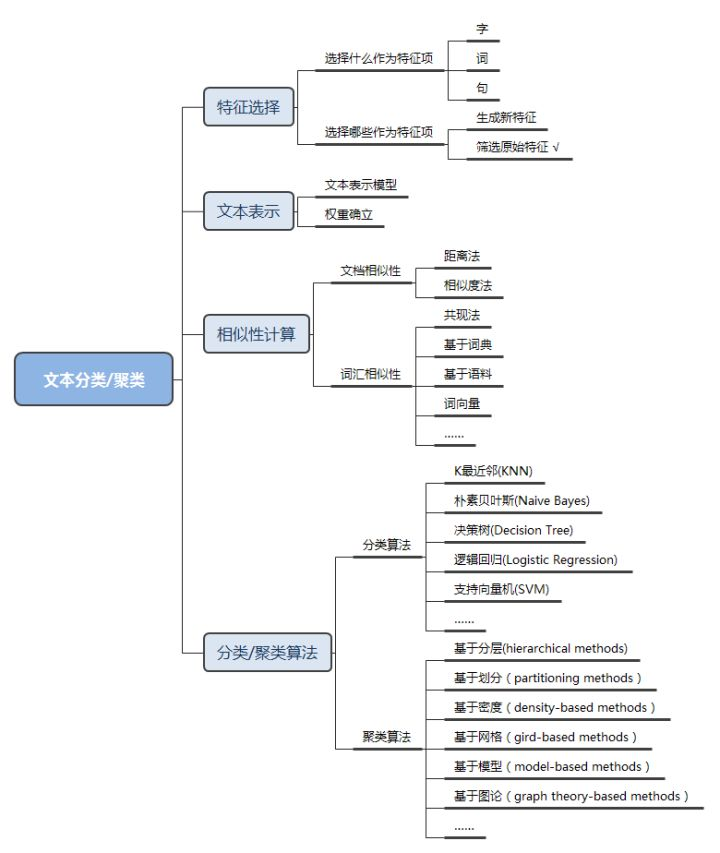
特征选择
用什么作为特征项
用于表示文本的基本单位通常称为文本的特征或特征项。特征项必须满足:能够标识文本内容、能够将目标文本与其他文本相区分、个数不能太多、特征项分离要比较容易实现。在中文文本中可以采用字、词或短语作为表示文本的特征项。
相比较而言,词比字具有更强的表达能力,而词和短语相比,词的切分难度比短语的切分难度小得多。因此,目前大多数中文文本分类系统都采用词作为特征项,称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算 。
选取哪些作为特征项
如果把所有的词都作为特征项,那么特征向量的维数将过于巨大,从而导致计算量太大,在这样的情况下,要完成文本分类几乎是不可能的。特征提取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。
特征选取的方式有2种:
用映射或变换的方法把原始特征变换为较少的新特征(将原始特征用新特征表示);
从原始特征中挑选出一些最具代表性的特征(只保留部分原始特征,不产生新特征),即根据某个特征评估函数计算各个特征的评分值,然后按评分值对这些特征进行排序,选取若干个评分值最高的作为特征词,常见的特征评估函数包括TF-IDF、信息增益、互信息等。
文本表示
如何表示文档
为了让计算机能够“计算”文本,就需要我们将文本数据转换成计算机可以处理的结构化数据。常见的文本表示模型有布尔模型、向量空间模型、统计主题模型等。其中,向量空间模型概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂,目前应用最广。
如何确立权重
一篇文档有很多词,有些词表达的语义很重要,有些相对次要,那么如何确定哪些重要?哪些次要呢?因此,需要进一步对每个词的重要性进行度量。常见的确立词汇权重的算法有TF-IDF、词频法等。
相似性计算
要实现文本的分类和聚类,需要设计一种算法计算出文档与文档、词汇与词汇之间的相似性。
文档相似性
设定我们要比较X和Y间的差异,它们都包含了N个维的特征,即X=(x1, x2, x3, … xn),Y=(y1, y2, y3, … yn)。下面来看看主要可以用哪些方法来衡量两者的差异,主要分为距离度量和相似度度量。
距离度量
距离度量(Distance)用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大。常见的距离有欧几里得距离(Euclidean Distance)、明可夫斯基距离(Minkowski Distance)、曼哈顿距离(Manhattan Distance)、切比雪夫距离(Chebyshev Distance)、马哈拉诺比斯距离(Mahalanobis Distance)。
相似性度量
相似度度量(Similarity),即计算个体间的相似程度,与距离度量相反,相似度度量的值越小,说明个体间相似度越小,差异越大。常见的相似性度量有向量空间余弦相似度(Cosine Similarity)、皮尔森相关系数(Pearson Correlation Coefficient)、Jaccard相似系数(Jaccard Coefficient)、调整余弦相似度(Adjusted Cosine Similarity)。
欧氏距离是最常见的距离度量,而余弦相似度则是最常见的相似度度量,很多的距离度量和相似度度量都是基于这的变形和衍生,所以下面重点比较下两者在衡量个体差异时实现方式和应用环境上的区别。下面借助三维坐标系来看下欧氏距离和余弦相似度的区别:
从图上可以看出距离度量衡量的是空间各点间的绝对距离,跟各个点所在的位置坐标(即个体特征维度的数值)直接相关;而余弦相似度衡量的是空间向量的夹角,更加的是体现在方向上的差异,而不是位置。如果保持A点的位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦相似度cosθ是保持不变的,因为夹角不变,而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
根据欧氏距离和余弦相似度各自的计算方式和衡量特征,分别适用于不同的数据分析模型:欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异;而余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦相似度对绝对数值不敏感)。
词汇相似性
目前接触的常见词汇相似性的方法有:
- 传统图情领域:基于共现频次这一基本统计量衍生出来的,如association strength、inclusion index、Jaccard’s coefficient、Salton’s cosine(Ochiia系数)等;
计算机领域:
- 是基于语义词典的方法,即依据词典分类体系挖掘所包含的词义知识,常用的词典包括Wordnet、Hownet等;
- 是基于语料库的方法,这里的语料库较为多元,例如百科预料、唐诗宋词预料等;
- 是进行词向量化,如Word2vec。
文本分类/聚类算法
有了文本表示方法,又有了计算相似性的公式,下一步就可以在此基础上讨论文本分类/聚类的算法了。
文本分类
医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
分类器是对样本进行分类的方法的统称,包含决策树、逻辑回归、朴素贝叶斯、神经网络等算法。举个例子:假如你想区分小明是好学生还是坏学生,那么区分“好学生”和“坏学生”就是一个分类任务。
K最邻近
“别和其他坏学生在一起,否则你也会和他们一样。” —— 家长
主要思想是通过离待预测样本最近的K个样本的类别来判断当前样本的类别。从K最近邻算法的角度来看,就是让目标样本与其他正样本距离更近、与其他负样本距离更远,从而使得其近邻中的正样本比例更高,更大概率被判断成正样本。
朴素贝叶斯
“根据以往抓获的情况来看,十个坏学生有九个爱打架。” —— 教导主任
“十个坏学生有九个爱打架”就意味着“坏学生”打架的概率P(打架|坏学生)=0.9,假设根据训导处历史记录坏学生占学生总数P(坏学生)=0.1、打架发生的概率是P(打架)=0.09,那么这时如果发生打架事件,就可以通过贝叶斯公式判断出当事学生是“坏学生”的概率P(坏学生|打架)=P(打架|坏学生)×P(坏学生)÷P(打架)=1.0,即该学生100%是“坏学生”。
决策树
“先看抽不抽烟,再看染不染头发,最后看讲不讲脏话。” ——社区大妈
假设“抽烟”、“染发”和“讲脏话”是社区大妈认为的区分“好坏”学生的三项关键特征,那么这样一个有先后次序的判断逻辑就构成一个决策树模型。在决策树中,最能区分类别的特征将作为最先判断的条件,然后依次向下判断各个次优特征。决策树的核心就在于如何选取每个节点的最优判断条件,也即特征选择的过程。
而在每一个判断节点,决策树都会遵循一套IF-THEN的规则:
IF “抽烟” THEN -> “坏学生” ELSE IF “染发” THEN -> “坏学生” ELSE IF “讲脏话” THEN -> “坏学生” ELSE -> “好学生”
逻辑回归
“上课讲话扣1分,不交作业扣2分,比赛得奖加5分。” ——纪律委员
我们称逻辑回归为一种线性分类器,其特征就在于自变量x和因变量y之间存在类似 y=ax+b 的一阶的、线性的关系。假设“上课讲话”、“不交作业”和“比赛得奖”的次数分别表示为x1、x2、和x3,且每个学生的基础分为0,那么最终得分 y=-1x1-2x2+5x3+0。其中 -1、-2和5分别就对应于每种行为在“表现好”这一类别下的权重。
对于最终得分y,逻辑回归还通过Sigmoid函数将其变换到0-1之间,其含义可以认为是当前样本属于正样本的概率,即得分y越高,属于“表现好”的概率就越大。也就是说,假如纪律委员记录了某位同学分别“上课讲话”、“不交作业”和“比赛得奖”各一次,那么最终得分y=-2-1+5=2,而对2进行Sigmoid变换后约等于0.88,即可知该同学有88%的概率为“好学生”。
支持向量机
“我想个办法把表现差的学生都调到最后一排。” ——班主任
支持向量机致力于在正负样本的边界上找到一条分割界线(超平面),使得它能完全区分两类样本的同时,保证划分出的间隔尽量的大。如果一条分割界线无法完全区分(线性不可分),要么加上松弛变量进行适当的容忍,要么通过核函数对样本进行空间上的映射后再进行划分。对于班主任来讲,调换学生们的座位就相当于使用了核函数,让原本散落在教室里的“好”、“坏”学生从线性不可分变得线性可分了。
文本聚类
基于分层的聚类
hierarchical methods:对数据集进行逐层分解,直到满足某种条件为止。可分为“自底向上”和“自顶向下”两种。例如“自底向上”指初始时每个数据点组成一个单独的组,在接下来的迭代中,按一定的距离度量将相互邻近的组合并成一个组,直至所有的记录组成一个分组或者满足某个条件为止。代表算法有:BIRCH,CURE,CHAMELEON等。自底向上的凝聚层次聚类如下图所示。

基于划分的聚类
partitioning methods:给定包含N个点的数据集,划分法将构造K个分组,每个分组代表一个聚类,这里每个分组至少包含一个数据点,每个数据点属于且仅属于一个分组。对于给定的K值,算法先给出一个初始的分组方法,然后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案较前一次好,这里好的标准在于同一组中的点越近越好,不同组中的点越远越好。代表算法有:K-means,K-medoids,CLARANS。K-means聚类过程图解如下:

基于密度的聚类
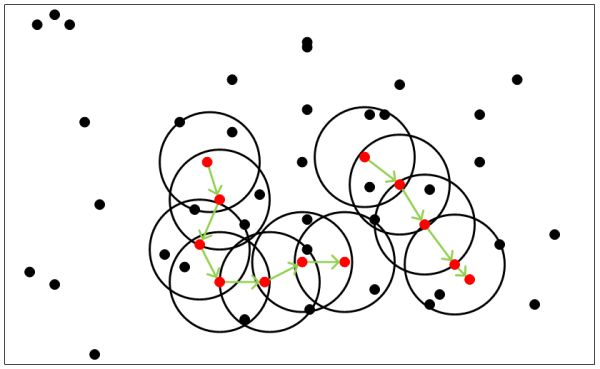
density-based methods:基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现“球形”聚簇的缺点。其核心思想在于只要一个区域中点的密度大于某个阈值,就把它加到与之相近的聚类中去。代表算法有:DBSCAN,OPTICS,DENCLUE,WaveCluster。DBSCAN的聚簇生成过程的简单理解如下图:
基于网格的聚类
gird-based methods:这种方法通常将数据空间划分成有限个单元的网格结构,所有的处理都是以单个的单元为对象。这样做起来处理速度很快,因为这与数据点的个数无关,而只与单元个数有关。代表算法有:STING,CLIQUE,WaveCluster。基于Clique的聚类过程可直观如下图进行理解。

基于模型的聚类
model-based methods:基于模型的方法给每一个聚类假定一个模型,然后去寻找能很好的拟合模型的数据集。模型可能是数据点在空间中的密度分布函数或者其它。这样的方法通常包含的潜在假设是:数据集是由一系列的潜在概率分布生成的。通常有两种尝试思路:统计学方法和神经网络方法。其中,统计学方法有COBWEB算法、GMM(Gaussian Mixture Model),神经网络算法有SOM(Self Organized Maps)算法。下图是GMM过程的一个简单直观地理解。

基于图论的聚类
图论聚类方法解决的第一步是建立与问题相适应的图,图的节点对应于被分析数据的最小单元,图的边(或弧)对应于最小处理单元数据之间的相似性度量。因此,每一个最小处理单元数据之间都会有一个度量表达,这就确保了数据的局部特性比较易于处理。图论聚类法是以样本数据的局域连接特征作为聚类的主要信息源,因而其主要优点是易于处理局部数据的特性。典型算法有谱聚类。
聚类问题的研究不仅仅局限于上述的硬聚类,即每一个数据只能被归为一类,模糊聚类也是聚类分析中研究较为广泛的一个分支。模糊聚类通过隶属函数来确定每个数据隶属于各个簇的程度,而不是将一个数据对象硬性地归类到某一簇中。目前已有很多关于模糊聚类的算法被提出,如著名的FCM算法等。
来自:
https://www.jianshu.com/p/5af7d0231ca2
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
嗯嗯,学到了